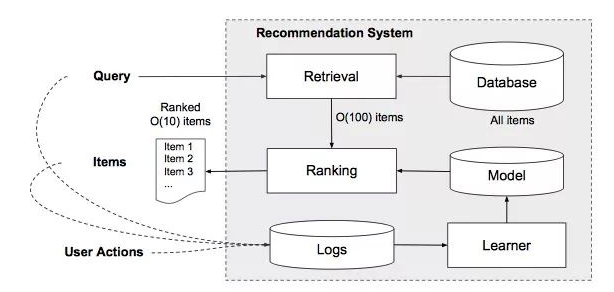
 上图是一个典型的推荐系统架构。
上图是一个典型的推荐系统架构。
- Query包含了 User Features, Contextual Features
- Item即被推荐的物品,常被称为Impression
- UserAction,如搜索结果是否被点击,广告是否被点击,电商物品是否被加入购物车等
推荐系统问题
推荐系统大概是应用最为广泛的机器学习系统。我们可以轻易举出很多例子。
- 搜索
- 搜索引擎本质上就是一个推荐系统
- 后搜索引擎时代的信息流推荐,比如今日头条,百度信息流等
- 电商
- 在Taobao等电商购物时,主动搜索和被动浏览的过程都可以认为是推荐问题
- 广告系统
- 展示广告(Display Ads)系统中每次展现时,根据content+user选择最佳广告
- 搜索广告(Search Ads)系统中每次搜索时,根据query+user选择最佳广告
常见的三种结构
- 待推荐物品个数较少时,Recommandation = Ranking
- 待推荐物品个数较多时,Recommandation = Retrieval + Ranking
- 需要结合运营等策略时,Recommandation = Retrieval + PreRank + Ranking + ReRank
通常,我们一般认为推荐系统有两个大的步骤,即Retrieval + Ranking。Retrieval这一步在国内一般也被称为召回(个人感觉用召回这个词不太直观)。
算法
内容实在太多了,这里参考脑图。
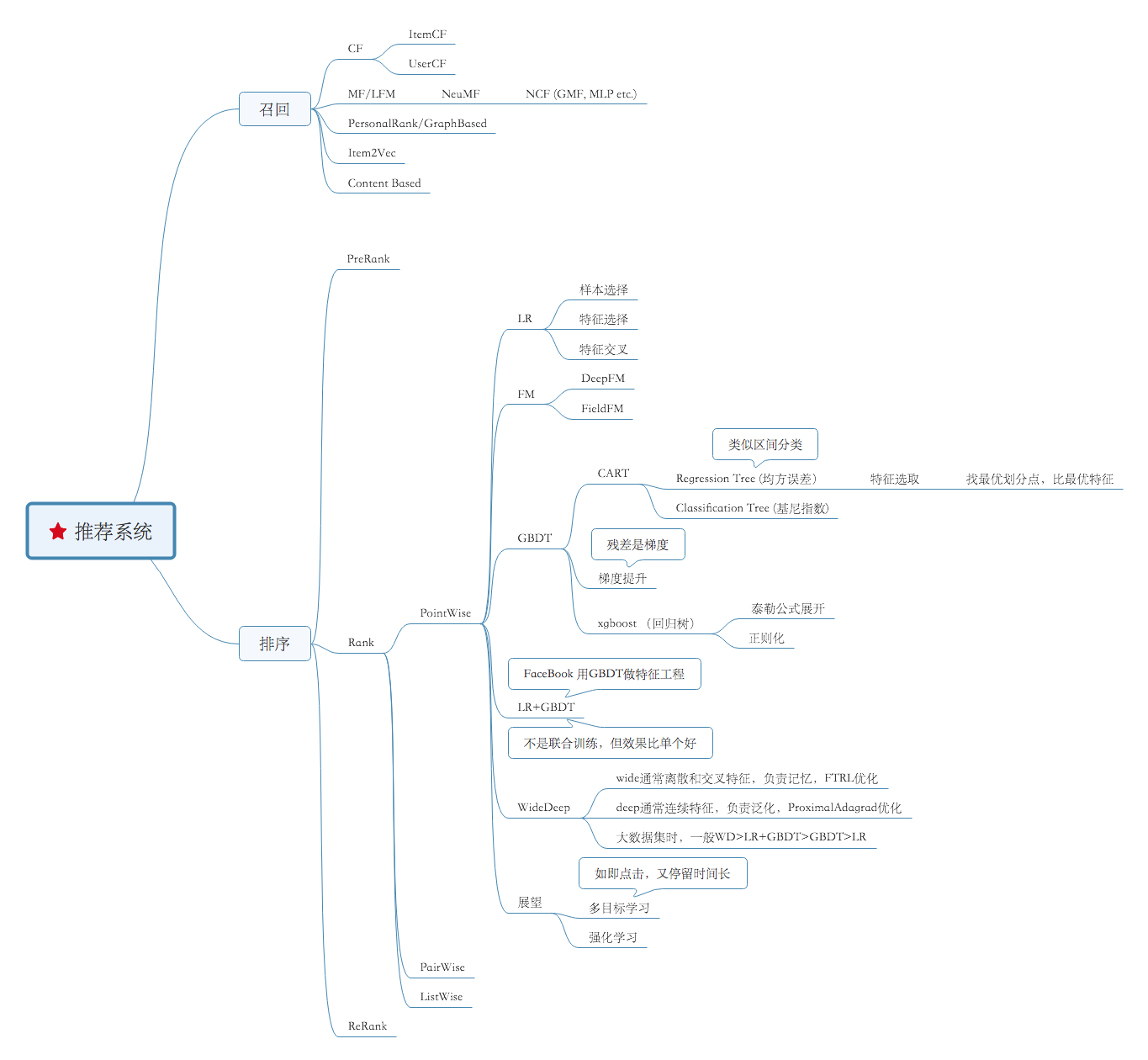
下面的内容仅供参考。
Retrieval
CF
- Item Based CF 利用item的相似性,喜欢M的也会喜欢N。
- User Based CF 用户A和B相似,A喜欢的B也会喜欢。
MF / LFM
MF是最简单有效的协同过滤算法。将feedback matrix近似分解为U和V。d是嵌入空间的纬度。

feedback matrix中有很多可能未被观察。

- 如果loss中不反映这些未被观察的,模型不够泛化。
- 如果将未被观测的当做0,可以简单用SVD求解。但由于未被观测的可能很多,这个矩阵会非常稀疏,SVD求解效率不高。
- 折中的做法是把未观测的当做0,但是加上一个总的权重。然后用WALS求解,即固定U,求V;固定V,求U,迭代。
DNN, NCF
DNN的做法是将user,item,query,side feature等信息输入DNN,DNN通过embedding(可以一层或多层)统一到d维,然后全连接到所有item做softmax。相当于进行了多分类。和MF相比较,DNN可以对side feature进行建模,且可以自动训练embedding。如果在DNN边上再加一个LR的话,就是Wide & Deep模型。
有可能item的个数n非常大,这个时候计算梯度需要将全连接的n个边都计算一遍会非常昂贵。如果我们只去计算正样本对应的item,则会碰到folding问题,即同类的嵌入是正确的,但不同类的嵌入可能会重叠。折中的思路是使用negative sampling。
negative sampling的策略就是从negative中选择一部分出来和positive一起计算梯度。
DNN和NCF思路上比较接近,都是用NN来解决问题。
Retrival的多个渠道
我们有可能用多个模型来做retrival,比如只考虑user item的MF,考虑side feature的DNN,统计的流行item等。多个渠道的候选集归并后作为最终的候选集。
检索
算法帮助我们对query做了embedding后,我们就可以最近邻找出相应的item(item的embedding提前算好索引好)。可以通过LSH等进行查找。
小结
- 性能
- 不太好比较一个绝对的优劣
- 没有本质的差别,数据噪音会把细微差异淹没,关键还是数据
- DEEP不一定有优势,xgboost也不错
Ranking
如果retrival使用了多个渠道,各个渠道还需要归并后混排。Retrival的输入数据量太大,不能使用太复杂的特征,ranking阶段我们可以使用更多特征做更复杂的模型。
Ranking常见的方案有
- point-wise, 对item个体做pCTR,常见算法有W&D, LR, FM, DeepFM等
- pair-wise, 对两个item做排序,只考虑前后关系
- list-wise,对多个item做排序,考虑具体的位置
TensorFlow Learn2Rank有非常好的介绍。
FM
LR的特征常很稀疏,需要做特征交叉。在LR基础上扩展出多项式模型,尤其是二项式模型。对二项式模型中的矩阵做分解。这样FM自动做了两个特征之间的特征交叉。
FFM是对FM的改进。一个原始特征被one-hot后多个bit都是属于同一个field的,考虑这个信息即FFM。
DeepFM
DeepFM是FM的扩展。
实例
-
NCF的开源实现: https://github.com/tensorflow/models/tree/master/official/recommendation
-
W&D的开源实现: https://github.com/tensorflow/models/tree/master/official/wide_deep
-
Learn2Rank的开源实现: https://github.com/tensorflow/ranking